
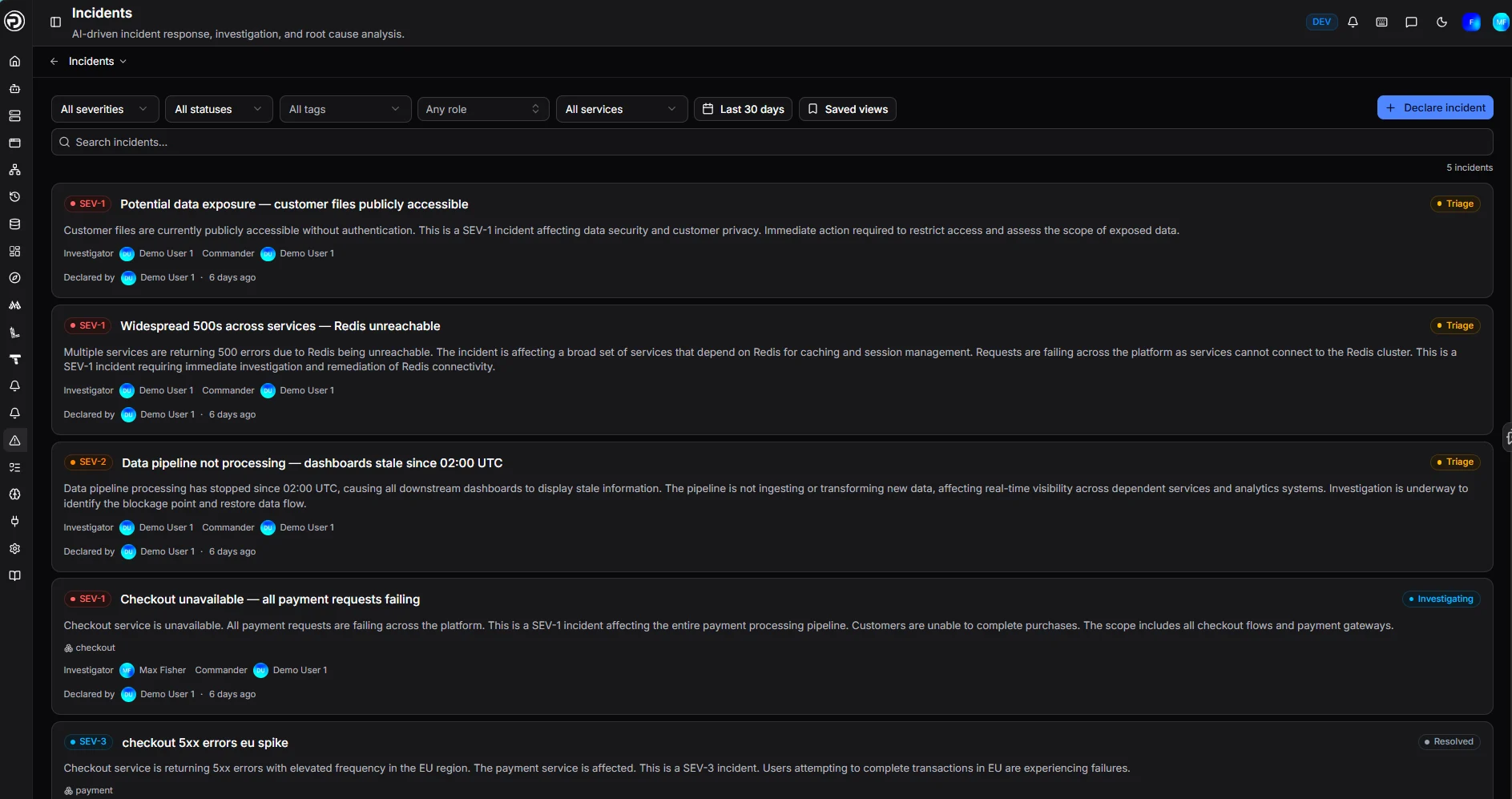
Stop fighting fires.
Start controlling them.
Re-engineered incident response — with a standardized lifecycle, precision alerting, and built-in accountability from triage to post-mortem.
4
Severity levels — SEV-1 to SEV-4
1
Unified workspace per incident
0
Action items lost after resolution
Live
Real-time timeline tracking
Severity System
One shared language
for every incident.
Ambiguous severity wastes minutes you don't have. OpsPilot standardizes on a clean four-tier model so every engineer on your team responds with the same urgency — automatically.
SEV-1
Critical outage. Full business impact. All hands on deck.
SEV-2
Major degradation. Key functionality impaired. Immediate response required.
SEV-3
Partial impact. Non-critical systems affected. Monitored response.
SEV-4
Minor issue. Low user impact. Scheduled investigation.
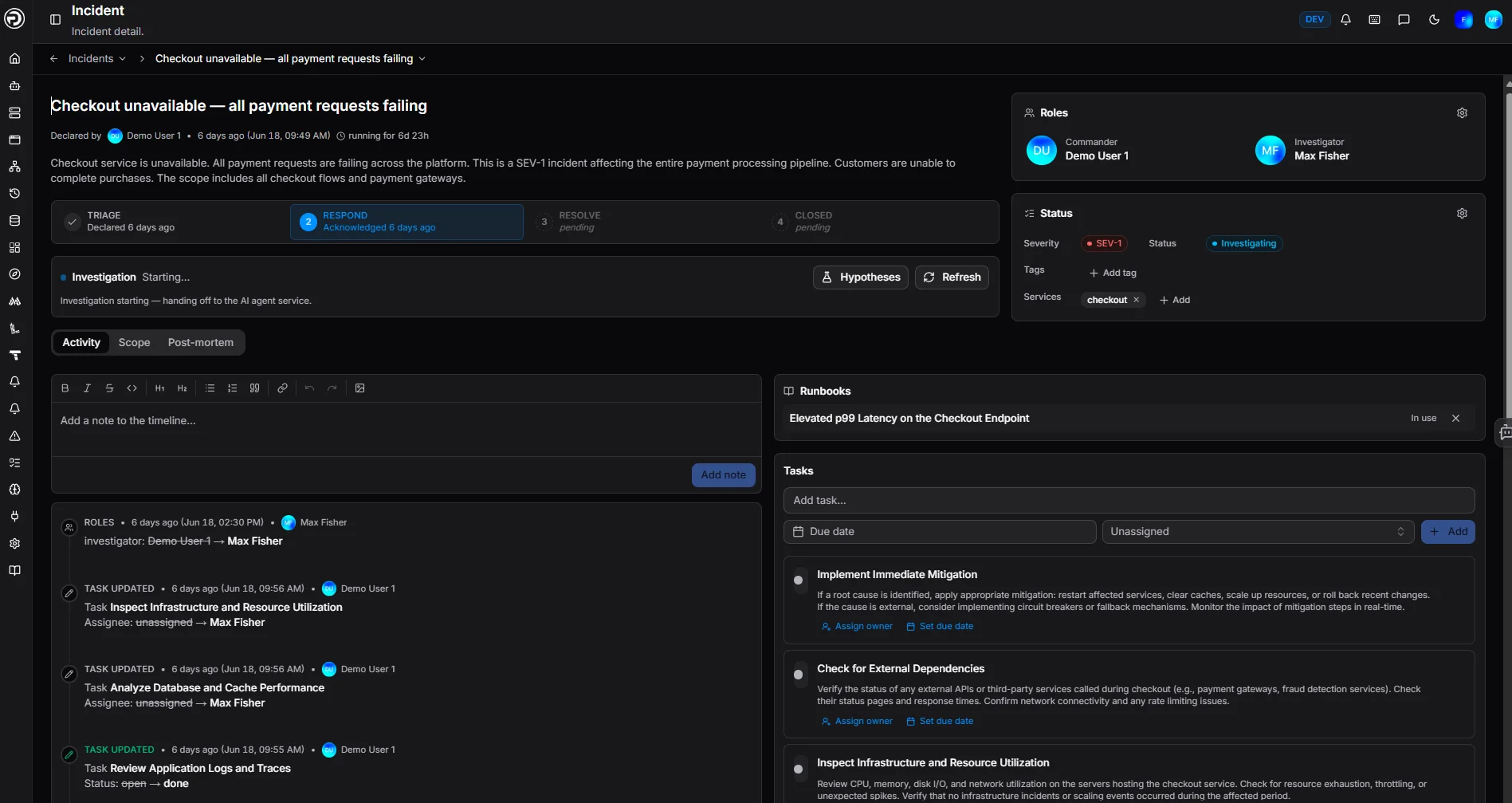
Live Activity Timeline
Everything that happened.
In order. In real time.
State changes, internal communications, and automated alerts flow into a single timeline — so anyone joining mid-incident gets up to speed in seconds, not minutes.
No more piecing together Slack threads and runbook comments. The incident record is the truth.
- Real-time state change tracking
- Internal comms logged alongside automated alerts
- Immutable audit trail for post-incident review
- Instantly visible to all incident participants
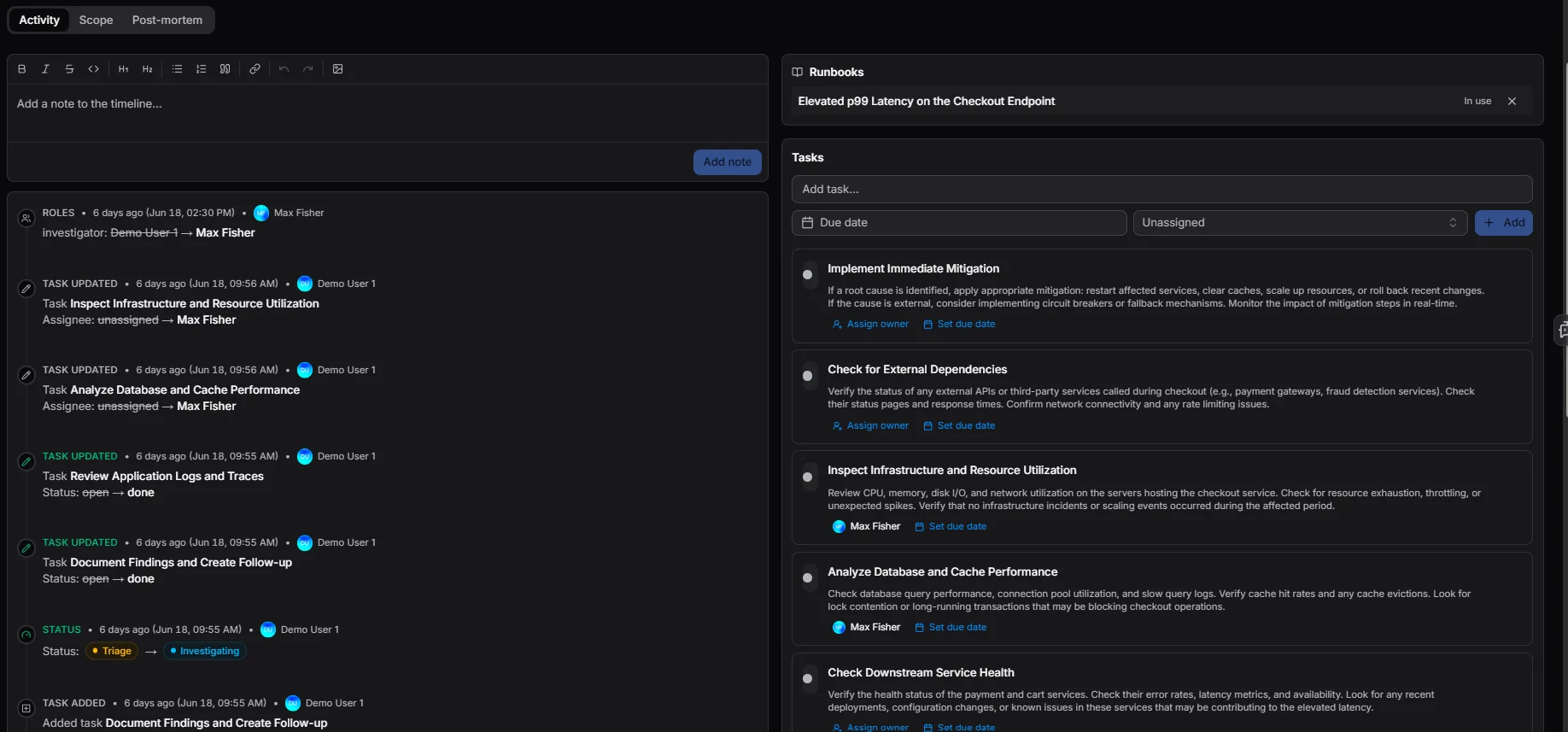
Contextual Sidebar
Everything you need.
Right where you are.
Active runbooks, linked services, SLA budgets, and ownership — consolidated in a persistent sidebar so your team never loses context during a high-pressure event.
No tab switching. No lost context. Everything visible, right now.
- Active runbooks with live step progress
- Linked services pulled from your Service Catalog
- Real-time SLA budget with breach warnings
- Incident ownership always in view
What's Included
Built for the full
incident lifecycle.
Post-Mortem Gatekeeper
Built-in post-mortem editors ensure remediation work is tracked and completed long after the incident closes — not abandoned in a doc nobody opens.

Tasks & Action Items
Every follow-up item, runbook action, and maintenance task lives on a unified board — connected to the incident that created it, so nothing falls through the cracks.

Precision Notifications
Get alerted the moment SLA budget approaches breach, an upstream dependency impacts your service, or a critical task drops onto your plate — never sooner, never later.
Service Catalog Integration
Every incident is automatically contextualized with ownership, service tiers, and dependencies from your catalog — giving Coworker AI the baseline it needs to triage faster.
Unified Workspace
Timeline, sidebar, runbooks, and communications — one screen, zero context switching. Designed for the speed and pressure of a live production incident.
Coming soon
Coworker AI — Autonomous Response
Coworker won't just provide context — it will step in. Proactively spin up incidents, assign tasks, page the right owners, and execute remediation steps autonomously.
Get Started
Faster response starts
today.
All Incidents features are live and rolled out to every OpsPilot workspace. No migration, no agents to swap out.
No form. No sales call required to start.