
The Most Revealing Number in Observability Tool Reviews Isn't What You'd Expect
When engineering teams evaluate observability platforms — whether they’re looking at AIOps tools, AI SRE platforms, or traditional monitoring — the conversation usually centers on features. Distributed tracing depth. Dashboard flexibility. OpenTelemetry compatibility. Integration counts.
So it’s striking that when those same teams go to G2 and leave reviews after months of real-world use, the category they consistently rate highest isn’t features at all.
It’s support.
See OpsPilot AI in action — start your free trial and see the support difference within 24 hours. No credit card required.
What the Data Actually Shows
Across G2 reviews of nine observability and AI SRE platforms — including New Relic, Splunk, PagerDuty, Grafana Labs, Sentry, SolarWinds, Digitate, Site24x7, and Better Stack — one pattern repeats consistently across every AI SRE and AI observability category.
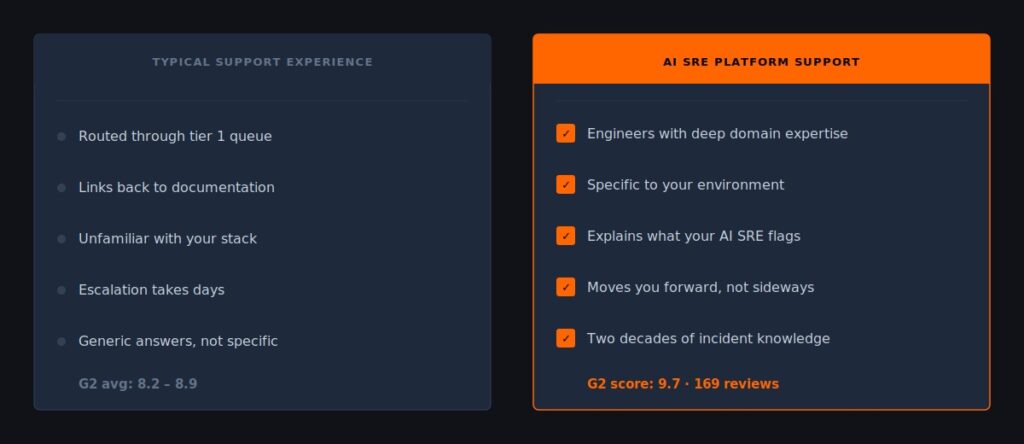
OpsPilot AI’s support quality score of 9.7 out of 10 on G2 is its single largest competitive advantage in every head-to-head comparison. Not product direction. Not ease of setup. Support.
The gaps are significant:
- vs New Relic: +1.4 points
- vs Splunk: +1.5 points
- vs Sentry: +1.5 points
- vs PagerDuty: +0.9 points
- vs Site24x7: +0.9 points
- vs Digitate: +1.3 points
- vs Better Stack: +0.8 points
In a market where most vendors score between 8.0 and 9.0 on support, a 9.7 is an outlier. And the consistency of that advantage — showing up in every single comparison — tells you something important about how it’s being delivered.
Why Support Quality Predicts More Than It Seems
Support quality on G2 isn’t just a proxy for “did someone reply quickly.” It captures something more specific: did the team feel genuinely helped when something was wrong?
That matters most in observability because the moments when you need support are almost always the worst moments in your operational week. Three services degrade simultaneously and none of your dashboards agree on why. In that situation, the difference between “here’s a link to the documentation” and “here’s exactly what’s happening in your environment and here’s what to do” is enormous. That’s not a feature difference. It’s a relationship difference — built over hundreds of incidents and two decades of APM experience.
It’s also worth noting what a high support score signals about the product itself. Tools that are genuinely well-designed and easy to reason about tend to generate better support experiences — because support teams can actually understand what a user is seeing and help them act on it. A 9.7 support rating is partly about people, and partly about the product being explainable.
The Tools That Score Highest on Support Tend to Have Something in Common
When you look across observability and AI SRE platforms on G2, the tools that score highest on support quality share a few characteristics.
They tend to be focused rather than sprawling. A platform trying to be the single pane of glass for every infrastructure concern — network, security, log aggregation, APM, synthetic monitoring, mobile performance — has a support team covering enormous surface area. When you raise a ticket, the person on the other end may have broad knowledge but thin depth on the specific thing you’re experiencing.
Focused platforms — especially those built around AI SRE, agentic operations, autonomous operations, and deep AI observability intelligence — tend to produce support teams that know their domain well. The problems users bring are more predictable. The answers are better.
They also tend to be built by people who’ve spent time on the other side of the incident. OpsPilot was built by teams with two decades of experience across AI SRE and observability — not people who read about production failures but people who’ve investigated thousands of them. That institutional knowledge shows up in support conversations.
What This Means When You’re Evaluating Tools
If you’re approaching a renewal decision — or evaluating alternatives to your current stack — support quality deserves more weight than most teams give it.
Here’s a practical way to think about it. During your trial or evaluation period, bring a real problem. Not a synthetic test scenario, but something from your actual environment — an alert pattern you don’t fully understand, a trace that’s behaving unexpectedly, a gap in your AI observability coverage you’ve been meaning to investigate.
How the support team responds tells you a great deal about what the next two years of working with that platform will feel like.
Questions worth asking:
- Did they engage with the specifics of your environment, or give you a generic answer?
- Did they understand what your AI SRE teammate was flagging, and why?
- Could they speak to your autonomous operations and agentic operations goals, not just the immediate issue?
- Did they help you move forward, or send you back to the documentation?
- Was the response time measured in hours or days?
A platform that scores 8.0 on support might be acceptable. A platform that scores 9.7 — consistently, across 169 reviews — is doing something structurally different.
The Honest Counterpoint
It’s worth being direct about what support quality doesn’t tell you.
A high support score doesn’t mean the product is perfect. It doesn’t mean you’ll never encounter a bug, a missing feature, or a rough edge. And it doesn’t mean support quality alone should drive a platform decision.
Feature coverage, OpenTelemetry-native AI SRE architecture, Grafana AI SRE dashboard integration, Prometheus AI SRE compatibility, pricing model — all of these matter. An AI SRE platform with exceptional support but weak agentic operations capabilities is still the wrong choice. And a strong AI SRE product with poor support will frustrate your team when it matters most.
What support quality does tell you is what happens after you buy. How well will problems get resolved? How fast will you get unstuck when something breaks? How much of your team’s time will get consumed by friction with the vendor versus friction with your actual production environment?
In our experience, the teams that regret switching observability platforms rarely cite missing features as the reason. They cite support experiences — the tickets that went unanswered, the renewal calls that replaced the engineering conversations, the feeling that once the contract was signed, the relationship changed.
A 9.7 support rating is the clearest signal available that a vendor takes that seriously.
Key Takeaways
- Support quality is consistently the strongest G2 differentiator for AI SRE platforms — not features, not price.
- A 9.7 support score across 169 reviews represents an institutional capability, not luck.
- High support ratings correlate with focused AI SRE platforms, deep domain expertise, and products that are genuinely explainable.
- When evaluating observability tools, use your trial period to test support quality with a real operational problem.
- Teams moving toward autonomous operations and autonomous SRE need a vendor partner who understands that journey — not just a ticket queue.
- The moment you most need support — services degrading, dashboards contradicting each other — is not the time to discover your vendor scores 8.1.
Start your free trial — see what a 9.7 support rating feels like in practice. No credit card required.
FAQ
Why does support quality score so high in observability tool reviews compared to other software categories?
Observability tools are used primarily during incidents — high-stress, time-sensitive situations where getting the wrong answer or a slow response has direct operational consequences. Support quality matters more in these contexts than in, say, productivity software, because the cost of a bad support experience is measured in downtime, not inconvenience.
What’s the difference between a 9.0 and a 9.7 support rating on G2?
On a 10-point scale, the difference between 9.0 and 9.7 is larger than it looks. G2 scores aggregate across many reviewers, and a 9.7 means the overwhelming majority of users rated support at the highest levels — not just “satisfied” but consistently exceptional. A 9.0 typically reflects solid but uneven support, while 9.7 reflects a structural commitment.
How should I test support quality during an observability platform trial?
Bring a real problem from your environment — not a test scenario. Ask a specific question about something you genuinely don’t understand. Observe response time, specificity, and whether the answer moves you forward or just redirects you to documentation. That interaction is a reliable predictor of what working with the vendor will feel like long-term.
Does OpsPilot’s high support rating reflect AI SRE expertise or just good customer service?
Both. OpsPilot was built by teams with two decades of observability and incident investigation experience. That domain depth shows up directly in support conversations — particularly around AI root cause analysis, AI incident investigation, and helping teams move toward autonomous operations. It’s not general-purpose helpfulness; it’s AI SRE expertise applied to your specific environment.
Is support quality a good reason to switch observability platforms?
It depends on what’s driving the evaluation. If you’re experiencing poor support from your current vendor — slow responses, generic answers, a feeling that the relationship deteriorated post-sale — then yes, it should factor heavily. If your current platform is working well and support isn’t a pain point, then other factors like AI observability capability, OpenTelemetry-native architecture, and pricing model should drive the decision.