
Everyone's Talking About AIOps. Here's What It Looks Like For a 50-Person Engineering Team.
The AIOps conversation in 2026 has an enterprise problem.
Most of the content written about AIOps — the analyst reports, the vendor keynotes, the case studies — describes AIOps at enterprise scale. Hundreds of engineers. Dedicated platform teams. Multi-year transformation programs. Six-figure implementation budgets.
This is not the reality for the majority of engineering organizations running production systems today. A 50-person engineering team does not have a dedicated observability platform team. It does not have a two-year runway for a transformation project. It does not have the budget for an enterprise AIOps contract.
What it does have is a production system that generates real incidents, real alert fatigue, real investigation time, and a real need for the analytical coverage that AIOps promises — delivered in a way that fits a mid-sized team’s actual constraints.
This post is about what an AIOps platform actually looks like for a team of that size. Not the enterprise vision. The practical reality.
Why The Enterprise AIOps Narrative Doesn’t Fit
The gap between how AIOps is marketed and how it needs to work for a 50-person team comes down to three things.
Implementation complexity. Enterprise AIOps platforms are typically sold with implementation services, professional services teams, and onboarding programs measured in months. A 50-person engineering team doesn’t have the capacity to absorb that. The implementation has to be lightweight — hours, not months — or it doesn’t happen.
Pricing model. Enterprise observability pricing typically scales with data volume, host count, or seats in ways that make the cost prohibitive for teams that aren’t already spending at enterprise scale. A team spending $5,000-10,000 per month on observability tooling cannot absorb an additional $50,000 per year for an AIOps layer on top.
Feature surface area. Enterprise AIOps platforms are built for the full enterprise IT operations stack — ITSM integration, change management, SLA management, capacity planning. A 50-person engineering team needs a fraction of this. The cognitive overhead of navigating features you don’t use is itself a cost.
What a 50-person team needs from an AIOps platform is the core value — proactive pattern detection, automated correlation, prioritized recommendations — delivered without the enterprise complexity, enterprise pricing, or enterprise implementation requirements.
As we explored in AIOps in 2026: What It Actually Means and Why Your Monitoring Tool Isn’t It, genuine AIOps is defined by what it automates — not by how many features it has or how large a team it was designed for.
What A 50-Person Team Actually Needs From AIOps
Strip away the enterprise requirements and the core AIOps value for a mid-sized team comes down to four practical outcomes.
1. Fewer incidents through proactive detection
The most valuable thing an AIOps platform does for a 50-person team is reduce the number of incidents that fire at 2am. Not by catching them faster once they’ve fired — by identifying the patterns that precede them and surfacing recommendations before impact occurs.
A team with 20 services instrumented with OpenTelemetry has enough telemetry data to detect most common failure patterns — connection pool exhaustion, memory leak trends, slow query degradation, upstream dependency issues — before they become incidents. As we documented in The 7 Patterns Behind 95% of Production Failures, these patterns are consistent and detectable. They just require something watching continuously.
For a 50-person team, every avoided incident is an outsized win. The on-call rotation is small. The bench of engineers who can respond at 2am is shallow. A platform that reduces incident frequency is directly reducing on-call burden on a team that feels that burden acutely.
2. Faster resolution when incidents do occur
When something does fire, the investigation phase is where mid-sized teams lose the most time. A 50-person team may not have a senior engineer who knows every service intimately. The person on call at 2am may be responding to an alert on a service they don’t own.
An AIOps platform that has already done the correlation work — matching the incoming alert pattern against known failure signatures, identifying the most likely root cause, surfacing the recommended action — compresses investigation from 90 minutes to 10. As detailed in You Have 10,000 Metrics. Why Does Root Cause Still Take 3 Hours?, eliminating the orientation and investigation phases is where the time savings are.
See what AIOps looks like in practice for a team your size. Start your free trial at app.opspilot.com/sign-up — no credit card required.
3. Cost optimization from existing telemetry
A 50-person team’s observability bill is a real budget line. At $5,000-15,000 per month for a properly instrumented stack, it’s a budget line that’s growing with system complexity and facing increased scrutiny.
An AIOps platform that continuously analyzes resource utilization metrics and surfaces specific cost optimization recommendations — unused Lambda functions, over-provisioned pods, idle database connections — generates savings that often offset its own cost within the first analysis cycle.
This is AIOps value that requires no new instrumentation, no new data collection, and no engineering work beyond reading a recommendation and acting on it. The cost signals are already in the metrics. The AIOps platform makes them visible.
4. Measurable improvement over time
A 50-person team needs to be able to show that their observability investment is working. Not because they’re under unusual scrutiny, but because measuring improvement is the only way to prioritize the right operational work.
Health scoring — tracking observability maturity, error rate management, performance, alerting effectiveness, and cost efficiency over time — gives a mid-sized team the same kind of operational KPI that enterprise teams have had for years. A health score that moves from 68 to 81 over a quarter is a story you can tell in a retrospective. It turns operational work from invisible maintenance into demonstrable progress.
What Implementation Actually Looks Like For A 50-Person Team
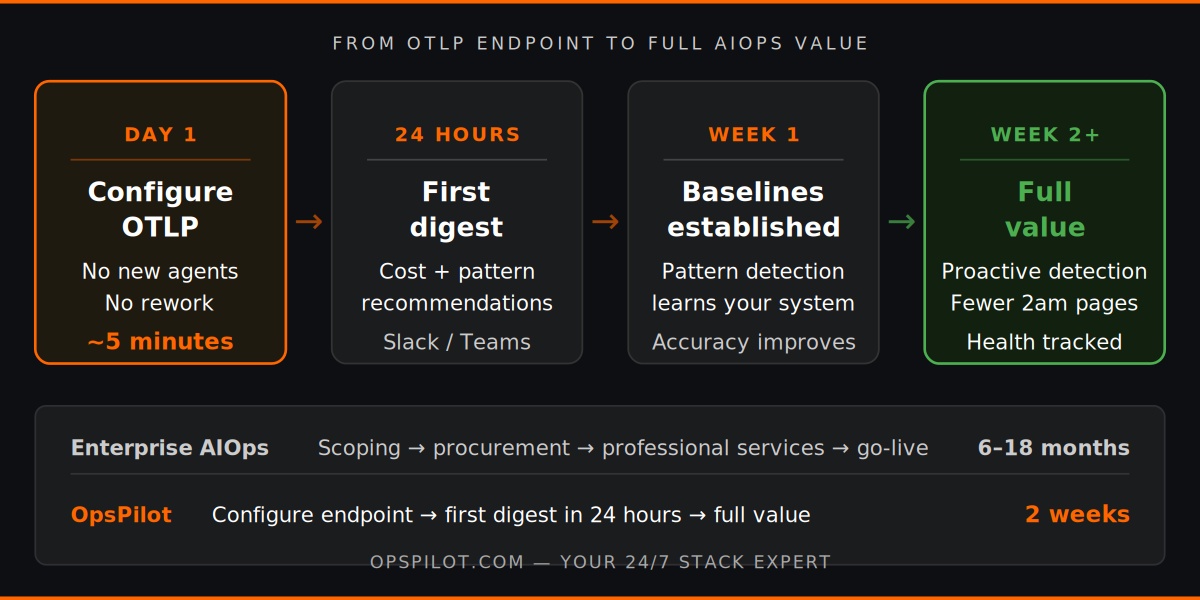
For a team already using OpenTelemetry — which most modern engineering teams are — connecting to an AIOps platform is not a project. It is a configuration task.
Day 1: Configure your OTLP endpoint to send data to OpsPilot alongside your existing backend. No changes to instrumentation. No migration of data. Five minutes of configuration.
Days 1-7: OpsPilot establishes baselines for your specific services and traffic patterns. The first analysis cycle runs within 24 hours and delivers an initial set of recommendations to Slack or Microsoft Teams — typically a mix of cost optimizations and performance patterns worth addressing.
Week 2 onwards: Pattern detection improves as baselines solidify. Recommendations become more specific to your system’s behavior. Health scoring tracks improvement across eight dimensions. The team starts replacing reactive investigation with proactive action.
There is no phase 2. There is no migration project. There is no dedicated implementation resource required. This is what makes AIOps accessible for a 50-person team in 2026 when it wasn’t in 2022.
As we covered in OpenTelemetry Without Intelligence Is Just Expensive Data Collection, the instrumentation is already in place for most teams. The intelligence layer is the missing piece — and connecting it takes hours, not months.
The Team Impact
What changes for a 50-person engineering team running AIOps is not primarily technical. It’s operational.
The on-call engineer goes from spending 90 minutes investigating to spending 10 minutes confirming and acting. The morning standup shifts from “we had an incident last night” to “we got a recommendation yesterday and fixed it before it became an incident.” The quarterly retrospective includes a health score chart showing measurable improvement rather than a list of incidents survived.
The senior engineers who previously spent time doing manual dashboard review — the kind of analysis that was valuable but never felt like the best use of their skills — spend that time on architectural work, feature development, and mentoring. The operational intelligence work is handled by the platform.
For a team where every engineer’s time is genuinely scarce, this reallocation is significant. The SRE talent picture for mid-sized teams in 2026 is not getting easier. AIOps is not a replacement for good engineering judgment. It is a way of making that judgment available for the work that requires it most.
The Right Questions To Ask
If you’re evaluating whether an AIOps platform makes sense for a team your size, these are the questions that matter:
Does it work with your existing OpenTelemetry data? The answer should be yes, via OTLP, without requiring re-instrumentation. If the first step is “migrate your data to our format,” the platform is optimizing for its own lock-in. See our OpenTelemetry capability page for how OpsPilot connects.
Can you be up and running in a day? A 50-person team cannot absorb a month-long implementation. If the vendor’s answer to “how long does implementation take” involves professional services, it’s not designed for your team size.
Is the pricing model predictable? Data volume-based pricing that scales unpredictably with system growth is the wrong model for a mid-sized team. You need to know what you’re paying and be confident it won’t spike with the next traffic surge.
Does it deliver conclusions or just more data? A genuine AIOps platform sends you a prioritized recommendation with a specific action. If it delivers another dashboard to check, it’s an observability tool with an AI badge — not an AIOps platform. As we explored in Dashboards Show You What Happened, the distinction matters.
Does it get better over time on your data specifically? The platform should be learning your system’s normal behavior patterns and improving recommendation accuracy as it operates. Generic rules applied to your specific context will generate generic — and often irrelevant — recommendations.
FAQ
Is AIOps only for large engineering teams? No. The core AIOps value — proactive pattern detection, automated correlation, prioritized recommendations — is if anything more impactful for smaller teams where on-call burden is concentrated and senior engineering time is most scarce. Enterprise AIOps platforms were designed for enterprise teams, but that’s a design choice, not a fundamental requirement of AIOps capability.
How much OpenTelemetry coverage do we need before AIOps adds value? Any meaningful coverage provides value. A team with ten services instrumented gets pattern detection and cost optimization on those ten services. A team with complete coverage across all services gets fuller analysis. OpsPilot’s gap detection capability surfaces which services would benefit most from additional instrumentation, helping teams prioritize coverage improvements that will have the most analytical impact.
What’s the minimum team size for AIOps to make sense? There’s no minimum. The ROI calculation is straightforward: if the time saved on incident investigation and the cost optimizations surfaced exceed the platform cost, AIOps delivers positive ROI regardless of team size. For teams handling more than two or three significant incidents per month, the time savings alone typically justify the investment.
How does OpsPilot pricing work for a 50-person team? See the full pricing breakdown at opspilot.com/pricing — no form, no sales call required. The model is designed to be predictable for mid-sized teams, not to scale unpredictably with data volume.

AIOps built for teams of 20-100 engineers. Not enterprise complexity. Real operational value.
Start your free trial at app.opspilot.com/sign-up
OpsPilot is an AI-powered observability intelligence platform that continuously analyzes your OpenTelemetry data and delivers prioritized recommendations, health scoring, and gap detection — directly to your team. Built by APM engineers with two decades of experience.